



















































Đào tạo AI và vấn nạn dữ liệu rác
Ngày đăng: 16/08/2024 14:09
Ngày đăng: 16/08/2024 14:09
Nếu cho một mô hình trí tuệ nhân tạo (AI) ăn những dữ liệu rác, thì đầu ra của mô hình đó cũng sẽ chỉ là rác.
 |
| Sử dụng hình ảnh do AI tạo ra để đào tạo AI sẽ nhanh chóng tạo ra một vòng lặp mà kết quả trở nên tồi tệ hơn về chất lượng hoặc đa dạng hình ảnh. |
Sự sụp đổ của mô hình
Các mô hình AI hoạt động bằng cách đào tạo trên những tập dữ liệu khổng lồ từ Internet. Chúng tìm kiếm các khuôn mẫu, quy luật trong dữ liệu này để có thể tạo ra văn bản, hình ảnh hoặc các loại nội dung khác. Nhưng khi ngày càng nhiều nội dung trên mạng được tạo ra bởi AI, nó sẽ tạo ra một vòng luẩn quẩn: AI mới học lại từ những nội dung chất lượng thấp, chứa nhiều thông tin trùng lặp hoặc sai lệch do các AI cũ tạo ra. Chúng ngấm vào mình những lỗi sai và thiếu sót trong dữ liệu mà kẻ tiền nhiệm đã làm ô nhiễm, dẫn đến chất lượng của các mô hình AI mới ngày càng giảm sút.
Điều này đã được minh chứng trong một nghiên cứu mới công bố trên tạp chí Nature hồi tháng bảy. Nhóm nghiên cứu đã đào tạo các mô hình ngôn ngữ lớn (LLM) bằng dữ liệu được tạo ra từ một mô hình tinh chỉnh khác và thấy rằng mô hình LLM sẽ suy giảm hiệu suất và “sụp đổ” hoàn toàn khi đạt đến thế hệ thứ chín.
Ilia Shumailov, nhà khoa học máy tính từ Đại học Oxford, người đứng đầu nghiên cứu này, so sánh quá trình đó với việc chụp ảnh: “Nếu chụp một bức ảnh, sau đó scan nó, rồi in ra, và lặp lại quá trình này nhiều lần, về cơ bản các điểm nhiễu ảnh sẽ lấn át toàn bộ quá trình. Cuối cùng, bạn chỉ còn lại một ô hình màu đen”. Trường hợp tương đương của ô hình màu đen với với AI được gọi là “sụp đổ mô hình”, có nghĩa là mô hình chỉ tạo ra những thứ vô nghĩa.
Nghiên cứu của Shumailov và các cộng sự có ý nghĩa quan trọng, bởi các mô hình AI lớn nhất hiện nay đang sử dụng Internet làm cơ sở dữ liệu của chúng. Ví dụ, GPT-3 của OpenAI được đào tạo từ một phần dữ liệu của Common Crawl, một kho lưu trữ trực tuyến gồm hơn ba tỷ trang web. Điều này có nghĩa là chất lượng của thông tin trên Internet ảnh hưởng trực tiếp đến chất lượng của mô hình GPT-3 và các mô hình dựa trên nó. Và vấn đề có thể trở nên tồi tệ hơn khi ngày càng nhiều trang web rác do AI tạo ra bắt đầu làm lộn xộn không gian Internet.
Shumailov nói rằng các mô hình AI hiện tại không chỉ có khả năng sụp đổ mà còn gặp những ảnh hưởng đáng kể bởi tốc độ cải tiến chậm lại và hiệu suất bị suy giảm. Để xác định tác động tiềm tàng lên hiệu suất, nhóm của ông đã tinh chỉnh một mô hình ngôn ngữ lớn LLM của Meta trên bộ dữ liệu từ Wikipedia, sau đó tiếp tục tinh chỉnh mô hình mới trên chính đầu ra của nó qua chín thế hệ. Họ đã đo mức độ vô nghĩa của đầu ra bằng cách sử dụng “điểm số bối rối”, đo lường độ tin cậy của mô hình AI trong việc dự đoán phần tiếp theo của một chuỗi. Điểm số cao hơn có nghĩa là một mô hình kém chính xác hơn.
Các mô hình được đào tạo bằng đầu ra của các mô hình khác có điểm số bối rối cao hơn. Ví dụ, trong mỗi thế hệ, nhóm nghiên cứu đều yêu cầu mô hình viết tiếp cho đoạn văn sau: “một số bắt đầu trước năm 1360 - thường được thực hiện bởi một thợ bậc thầy và một nhóm nhỏ thợ xây lưu động, được bổ sung bởi các lao động giáo xứ địa phương, theo Poyntz Wright. Nhưng các tác giả khác bác bỏ mô hình này, cho rằng thay vào đó các kiến trúc sư hàng đầu đã thiết kế các tháp nhà thờ giáo xứ dựa trên các ví dụ ban đầu về Perpendicular [kiến trúc]” (Đoạn này trích trong bài viết về tháp Somerset trên Wikipedia).
Ở thế hệ thứ nhất, mô hình viết tiếp rằng: “kiến trúc như Vương cung thánh đường thánh Peter ở Rome hay Vương cung thánh đường thánh Peter ở Buenos Aires. Không có bằng chứng cho thấy bất kỳ tòa nhà nào trong số này được xây dựng dưới triều đại của Giáo hoàng Innocent III, nhưng có thể chúng đã được xây dựng dưới triều đại của người kế nhiệm ông, Giáo hoàng Innocent.”
Nhưng đến thế hệ thứ chín, mô hình đã viết tiếp thành một đoạn văn hoàn toàn vô nghĩa: “kiến trúc. Ngoài việc là nhà của một số quần thể lớn nhất của @-@ thỏ rừng đuôi đen, @-@ thỏ rừng đuôi trắng, @-@ thỏ rừng đuôi xanh, @-@ thỏ rừng đuôi đỏ, @-@ đuôi vàng.”
Shumailov giải thích hiện tượng này bằng cách sử dụng một phép so sánh: Hãy tưởng tượng bạn đang cố tìm một cái tên ít phổ biến nhất của học sinh trong trường. Bạn có thể xem qua danh sách tên của tất cả học sinh, nhưng sẽ mất quá nhiều thời gian. Thay vào đó, bạn xem qua 100 tên trong số 1000 tên. Bạn sẽ có một ước lượng khá tốt, nhưng có lẽ không phải là câu trả lời chính xác. Bây giờ, hãy tưởng tượng một người khác đến và ước lượng dựa trên 100 cái tên của bạn đã chọn, nhưng họ chỉ chọn xem có 50 tên thôi. Ước lượng của người thứ hai này sẽ còn kém chính xác hơn người thứ nhất.
“Bạn có thể hình dung điều tương tự xảy ra với các mô hình học máy. Nếu mô hình đầu tiên đã xem một nửa Internet, thì có lẽ mô hình thứ hai sẽ không cần phải xem hết một nửa Internet mà chỉ cần thu thập 100.000 bài tweet mới nhất rồi điều chỉnh mô hình theo đó”, anh nói.
Truy xuất dữ liệu
Internet không có lượng dữ liệu vô hạn. Để tiếp tục phát triển, các mô hình AI tương lai có thể cần sử dụng dữ liệu tổng hợp (do AI tạo ra) thay vì chỉ dựa vào dữ liệu thực tế. Hiện nay, các mô hình nền tảng lớn đã bắt đầu tìm đến các bộ dữ liệu tổng hợp được tạo ra trong môi trường có kiểm soát để giải quyết vấn đề của mình, vì nếu cứ tiếp tục thu thập thêm dữ liệu từ trên web thì hiệu quả mô hình sẽ giảm dần.
Matthias Gerstgrasser, nhà nghiên cứu AI tại Đại học Stanford, tác giả của một bài báo kiểm tra sự sụp đổ của mô hình đăng trên nền tảng Arxiv hồi tháng tư nói rằng, việc bổ sung dữ liệu tổng hợp vào bên cạnh dữ liệu thực tế (thay vì thay thế cho dữ liệu thực tế) sẽ không gây ra vấn đề lớn. Nhưng Matthias cũng nói thêm rằng, tất cả các tài liệu nghiên cứu về sự suy giảm mô hình hiện nay đều đồng ý dữ liệu đào tạo cho mô hình phải là các dữ liệu đa dạng và có chất lượng cao.
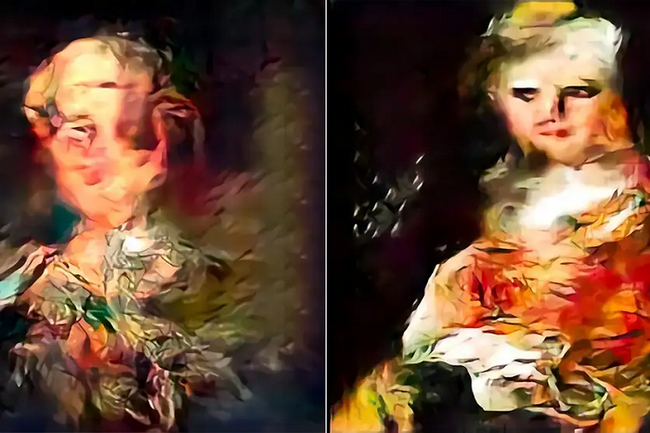 |
| AI tạo ra hình ảnh mờ và kém thực tế hơn khi được đào tạo trên các tập dữ liệu do AI tạo ra. |
Một hiệu ứng khác của sự suy giảm chất lượng mô hình theo thời gian, đó là thông tin liên quan đến các nhóm thiểu số bị bóp méo nặng nề, vì mô hình sẽ có xu hướng tập trung quá mức vào những mẫu phổ biến hơn trong tập dữ liệu huấn luyện. Trong các mô hình hiện tại, điều này có thể ảnh hưởng đến các ngôn ngữ ít được đại diện, vì chúng dùng nhiều tập dữ liệu tổng hợp để huấn luyện hơn, theo Robert Mahari, người nghiên cứu luật tính toán tại phòng thí nghiệm MIT Media Lab.
Một cách để tránh suy giảm mô hình là đảm bảo mô hình ưu tiên dữ liệu gốc do con người tạo ra hơn. Nghiên cứu của Shumailov cho thấy, nếu cho phép các mô hình thế hệ tiếp theo lấy một phần nhỏ (10%) của dữ liệu gốc thì có thể hạn chế bớt một số tác động tiêu cực.
Cách tiếp cận này yêu cầu phải thiết lập được một dấu vết từ dữ liệu gốc do con người tạo ra đến các phiên bản tiếp theo, được gọi là truy xuất nguồn gốc dữ liệu (data provenance). Nhưng để truy được nguồn gốc dữ liệu, cần phải có cách phân biệt giữa nội dung do con người tạo ra và nội dung do AI tạo ra. Hiện tại, chúng ta vẫn chưa có cách chính xác để phân biệt hai loại nội dung này. Mặc dù đã có một số công cụ nhằm xác định liệu văn bản có phải do AI tạo ra hay không nhưng độ chính xác của chúng vẫn còn rất hạn chế.
“Thật không may, chúng ta đang có nhiều câu hỏi hơn câu trả lời,” Shumailov nói. “Nhưng rõ ràng điều quan trọng là phải biết dữ liệu của bạn đến từ đâu và bạn có thể tin tưởng nó đến mức nào để phản ánh thực tại.”
Khoahocphattrien